
In this article, we will explore the seamless integration of Amazon Titan, a foundational model from Amazon Bedrock, with a Spring Boot application. We will share slight insight on the process of generating embeddings using Amazon Titan and demonstrate how to harness the power of this advanced AI capability within the Spring framework.
This article is structured into multiple sections to streamline the stages involved in creating a domain-based AI assistant using RAG and prompt engineering.
- Amazon Bedrock: Revolutionizing Generative AI Applications
- Developing a Spring Boot Application with Amazon Bedrock API
- Leveraging Amazon Titan with Spring Boot: A Guide to Generating Embeddings
- Navigating the Vector Database Universe with Spring Boot and MongoDB
- The Art of Prompt Engineering: Optimizing GPT Models for Enhanced Performance
Introduction to Embeddings
Embeddings are a fundamental concept in natural language processing and machine learning. They are a way to represent words, phrases, or documents as vectors in a high-dimensional space, where the distance and direction between vectors capture semantic relationships. Amazon Titan supports the generation of text and multimodal embeddings, offering a powerful tool for various use cases, from information retrieval to content recommendation.
Significance of Embeddings
- Semantic Relationships: Embeddings enable models to understand the semantic relationships between entities. Words with similar meanings are represented by vectors that are close in the embedding space.
- Contextual Understanding: Embeddings capture contextual information, allowing algorithms to discern nuances and subtle differences in meaning, enhancing the accuracy of various NLP tasks.
- Dimensionality Reduction: Embeddings effectively reduce the dimensionality of the data, retaining essential information while minimizing computational complexity.
- Transfer Learning: Pre-trained embeddings, such as those learned from large language models, can be transferred and fine-tuned for specific tasks, saving training time and resources.
Generating Embeddings
We will continue to enhance our Assistant spring-boot application to generate embeddings using Amazon Titan foundational model. Please refer article Developing a Spring Boot Application with Amazon Bedrock API for steps on integrating Amazon Bedrock API’s.
Update Controller
Update AssistantController.java to add new post method endpoint for generating vector embeddings.
AssistantController.java
package com.slightinsight.assist.web;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import com.slightinsight.assist.model.Prompt;
import com.slightinsight.assist.service.AssistantService;
@RestController
@RequestMapping("/api/assist")
public class AssistantController {
@Autowired
private AssistantService assistantService;
@GetMapping(value = "/public/ask")
public ResponseEntity<String> askAssistant(@RequestBody Prompt prompt) {
String response = assistantService.askAssistant(prompt);
return new ResponseEntity<String>(response, HttpStatus.OK);
}
@PostMapping(value = "/public/save-embeddings")
public ResponseEntity<String> saveEmbeddings(@RequestBody Prompt prompt) {
String response = assistantService.saveEmbeddings(prompt);
return new ResponseEntity<String>(response, HttpStatus.OK);
}
}Update Service
Next step to updated AssistantService.java to add function for generating embeddings.
AssistantService.java
package com.slightinsight.assist.service;
import java.util.List;
import java.util.concurrent.atomic.AtomicReference;
import org.json.JSONObject;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import com.slightinsight.assist.model.Prompt;
import software.amazon.awssdk.core.SdkBytes;
import software.amazon.awssdk.services.bedrockruntime.BedrockRuntimeAsyncClient;
import software.amazon.awssdk.services.bedrockruntime.BedrockRuntimeClient;
import software.amazon.awssdk.services.bedrockruntime.model.InvokeModelRequest;
import software.amazon.awssdk.services.bedrockruntime.model.InvokeModelResponse;
import software.amazon.awssdk.services.bedrockruntime.model.InvokeModelWithResponseStreamRequest;
import software.amazon.awssdk.services.bedrockruntime.model.InvokeModelWithResponseStreamResponseHandler;
@Service
public class AssistantService {
private static final String CLAUDE = "anthropic.claude-v2";
private static final String TITAN = "amazon.titan-embed-text-v1";
@Autowired
private BedrockRuntimeClient bedrockClient;
@Autowired
private BedrockRuntimeAsyncClient bedrockAsyncClient;
public String askAssistant(Prompt prompt) {
String response = "";
// Claude requires you to enclose the prompt as follows:
String enclosedPrompt = "Human: " + prompt.getQuestion() + "\n\nAssistant:";
if (prompt.getResponseType().equals("SYNC"))
response = syncResponse(enclosedPrompt);
else if (prompt.getResponseType().equals("ASYNC"))
response = asyncResponse(enclosedPrompt);
return response;
}
/*
* * Synchronous call to AI for text response
*/
private String syncResponse(String enclosedPrompt) {
String payload = new JSONObject().put("prompt", enclosedPrompt)
.put("max_tokens_to_sample", 200)
.put("temperature", 0.5)
.put("stop_sequences", List.of("\n\nHuman:")).toString();
InvokeModelRequest request = InvokeModelRequest.builder().body(SdkBytes.fromUtf8String(payload))
.modelId(CLAUDE)
.contentType("application/json")
.accept("application/json").build();
InvokeModelResponse response = bedrockClient.invokeModel(request);
JSONObject responseBody = new JSONObject(response.body().asUtf8String());
String generatedText = responseBody.getString("completion");
System.out.println("Generated text: " + generatedText);
return generatedText;
}
/*
* * Streaming call to AI for text response
*/
private String asyncResponse(String enclosedPrompt) {
var finalCompletion = new AtomicReference<>("");
var silent = false;
var payload = new JSONObject().put("prompt", enclosedPrompt).put("temperature", 0.8)
.put("max_tokens_to_sample", 300).toString();
var request = InvokeModelWithResponseStreamRequest.builder().body(SdkBytes.fromUtf8String(payload))
.modelId(CLAUDE).contentType("application/json").accept("application/json").build();
var visitor = InvokeModelWithResponseStreamResponseHandler.Visitor.builder().onChunk(chunk -> {
var json = new JSONObject(chunk.bytes().asUtf8String());
var completion = json.getString("completion");
finalCompletion.set(finalCompletion.get() + completion);
if (!silent) {
System.out.print(completion);
}
}).build();
var handler = InvokeModelWithResponseStreamResponseHandler.builder()
.onEventStream(stream -> stream.subscribe(event -> event.accept(visitor))).onComplete(() -> {
}).onError(e -> System.out.println("\n\nError: " + e.getMessage())).build();
bedrockAsyncClient.invokeModelWithResponseStream(request, handler).join();
return finalCompletion.get();
}
public String saveEmbeddings(Prompt prompt) {
String payload = new JSONObject().put("inputText", prompt.getQuestion()).toString();
InvokeModelRequest request = InvokeModelRequest.builder().body(SdkBytes.fromUtf8String(payload)).modelId(TITAN)
.contentType("application/json").accept("application/json").build();
InvokeModelResponse response = bedrockClient.invokeModel(request);
JSONObject responseBody = new JSONObject(response.body().asUtf8String());
return responseBody.getJSONArray("embedding").toString();
}
}
Amazon Titan API : Test Run
We can run this app by issuing below command:
Command
mvn spring-boot:run
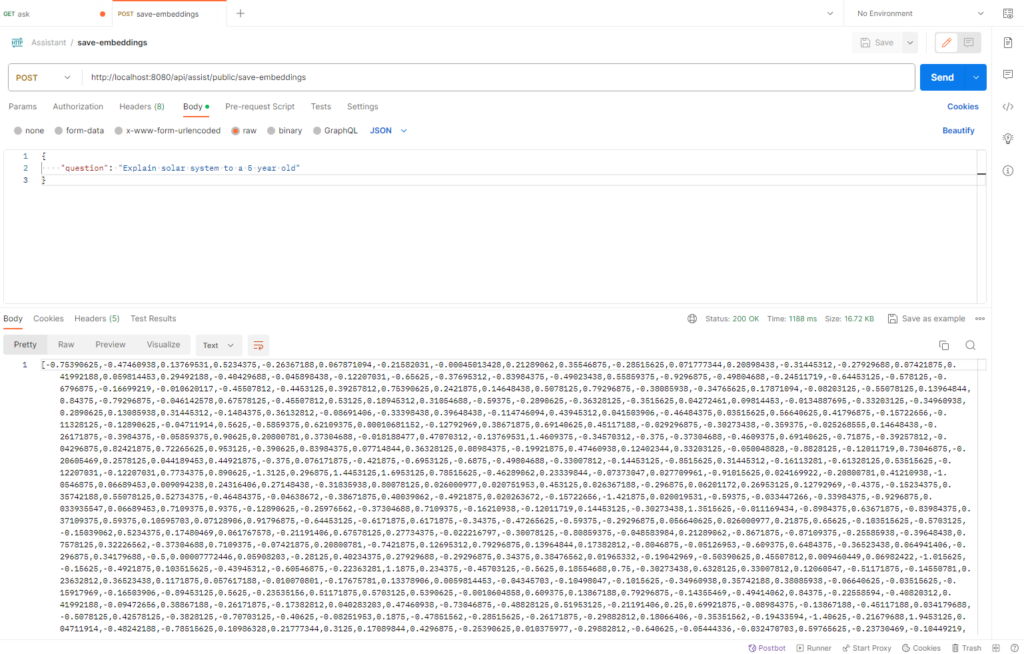
Once the app is running, try generating embeddings by using below API endpoint url:
URL & Request Body
http://localhost:8080/api/assist/public/save-embeddings
Request Body:
{
"question": "Explain solar system to a 5 year old"
}If everything goes well, we will receive the response as below in postman:
Git Code: AssistantAI
Conclusion:
The integration of Spring Boot with Amazon Titan Bedrock APIs provides developers with a robust platform for harnessing the power of embeddings. Whether you’re working on NLP applications, recommendation systems, or other AI-driven projects, embeddings play a crucial role in enhancing the understanding of data. By incorporating embeddings into your Spring Boot applications with the support of Titan Bedrock APIs, you open doors to more sophisticated and context-aware solutions.
In the next article we will explore Vector Database and how to save embedding into it.
As the demand for AI-powered applications continues to rise, mastering techniques like embeddings becomes increasingly valuable. The synergy between Spring Boot and Amazon Titan Bedrock APIs empowers developers to seamlessly implement embedding generation and leverage the benefits of this powerful representation method. Stay tuned for more insights into cutting-edge technologies on our blog at slightinsight.com!




Leave a Reply
You must be logged in to post a comment.