
Hey there, tech enthusiasts! Welcome back to Slight Insight. Today, we’re diving into the world of vector databases and how to integrate them with a Spring Boot application. But first, let’s start with the basics.
This article is structured into multiple sections to streamline the stages involved in creating a domain-based AI assistant using RAG and prompt engineering.
- Amazon Bedrock: Revolutionizing Generative AI Applications
- Developing a Spring Boot Application with Amazon Bedrock API
- Leveraging Amazon Titan with Spring Boot: A Guide to Generating Embeddings
- Navigating the Vector Database Universe with Spring Boot and MongoDB
- The Art of Prompt Engineering: Optimizing GPT Models for Enhanced Performance
What is a Vector Database?
A vector database, also known as a vector search database or vector similarity search engine, is designed to store, retrieve, and search for vectors. In the context of AI and machine learning, a vector represents a quantity that has both magnitude and direction. A vector database is tailored to efficiently process vast volumes of vectorized data, ensuring faster queries and processing speeds.
MongoDB as Vector Database
MongoDB is not just your typical NoSQL database; it’s a versatile powerhouse that seamlessly accommodates vectors. Its dynamic schema, scalability, and robust indexing capabilities make it an ideal choice for storing and querying vector data efficiently.
The introduction of Atlas Vector Search by MongoDB has eliminated the need to store vectors separately from operational data, thus avoiding inefficiencies in applications. This capability allows for efficient vector storage in the operational database, enabling seamless querying of vector data using familiar syntax. By integrating vector search capabilities within MongoDB Atlas, users can benefit from the performance advantages of an optimized vector database without the need for additional syncing between different solutions.
Prerequisites
To create an Atlas Vector Search index, you must have an Atlas cluster with the following prerequisites:
- MongoDB version
6.0.11,7.0.2, or higher - A collection for which create the Atlas Vector Search index
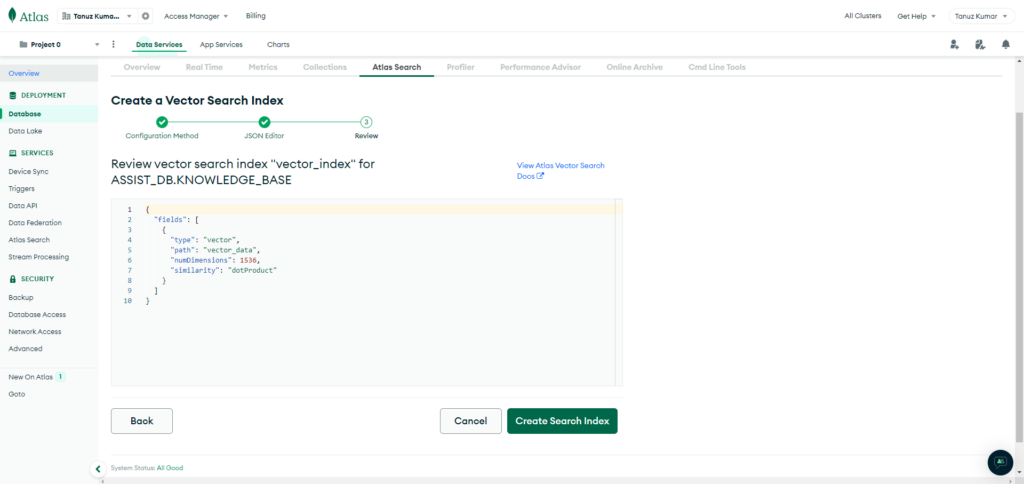
Steps to create Vector Index in MongoDB Atlas
Login into MongoDB Atlas account.
Create collection KNOWLEDGE_BASE under database ASSIST_DB and click on Atlas Search tab.
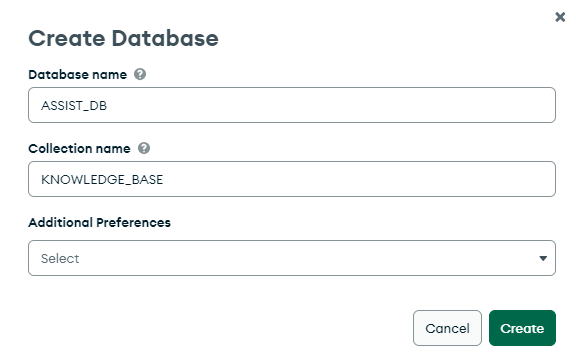
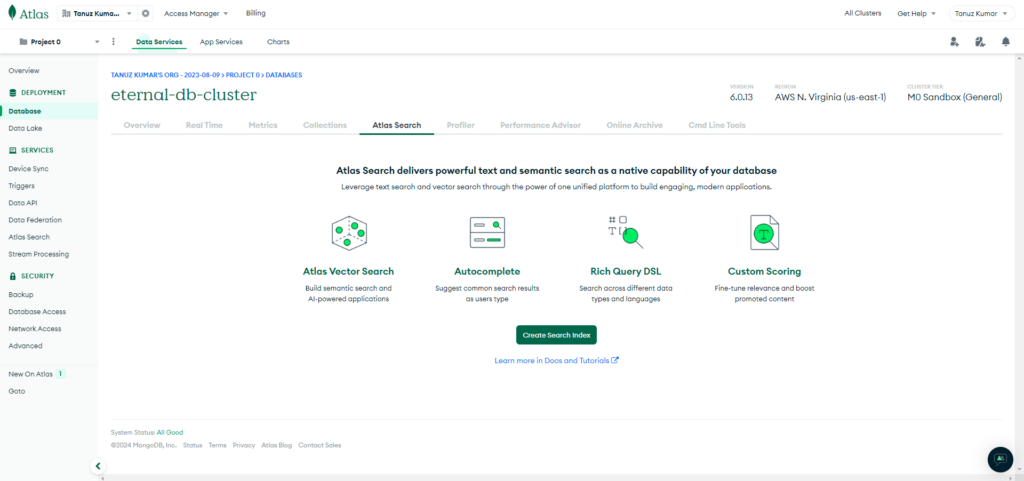
Click on Create Search Index button.
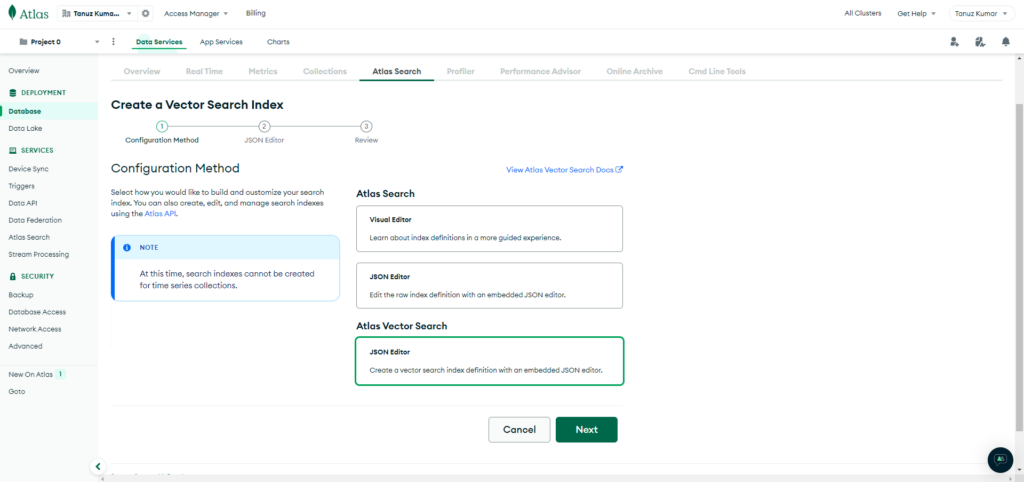
Select JSON Editor under Atlas Vector Search and click Next.
Enter the Index Name as vector_index, and set the Database and Collection.
Specify index definition
- “path”: “vector_data” // The field name in the collection on which index will be created
- “numDimensions”: 1536 //The Amazon Titan Embeddings G1 – Text v1.2 can intake up to 8k tokens and outputs a vector of 1,536 dimensions.
- “similarity”: “dotProduct” //Vector similarity function to use to search for top K-nearest neighbors.
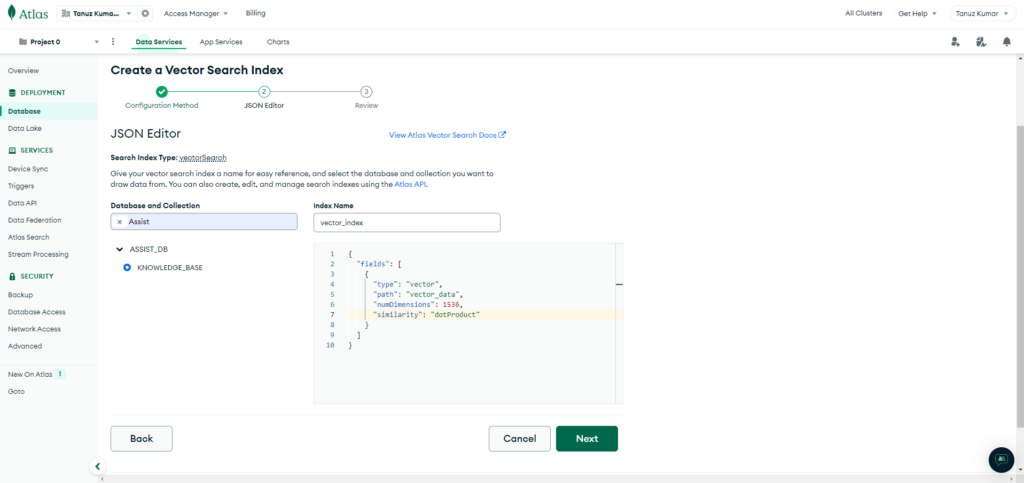
Review the index definition and click on Create Search Index button.
Storing Embeddings in Vector Database
We will continue to enhance our Assistant spring-boot application to store generated embeddings using Amazon Titan foundational model in MongoDB Atlas database. Please refer article Leveraging Amazon Titan with Spring Boot: A Guide to Generating Embeddings for steps on generating embeddings using Amazon Bedrock API’s.
Update dependencies
Open pom.xml and add mongodb dependencies.
Maven
<dependencyManagement>
<dependencies>
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>bom</artifactId>
<version>2.21.17</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>bedrock</artifactId>
</dependency>
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>bedrockruntime</artifactId>
</dependency>
<dependency>
<groupId>org.json</groupId>
<artifactId>json</artifactId>
<version>20231013</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>Update Application Properties
Open application.properties under “src/main/resources” and add MongoDB properties.
application.properties
#aws configration
cloud.aws.credentials.access-key=YOUR_ACCESS_KEY
cloud.aws.credentials.secret-key=YOUR_SECRET_KEY
cloud.aws.region.static=AWS_REGION
#mongodb configuration
spring.data.mongodb.uri=YOUR_MONGODB_URI
spring.data.mongodb.database=ASSIST_DB
Configure MongoDB
Under package “com.slightinsight.assist.config” add the class “MongoConfig.java“.
MongoConfig.java
package com.slightinsight.assist.config;
import com.mongodb.ConnectionString;
import com.mongodb.MongoClientSettings;
import com.mongodb.client.MongoClient;
import com.mongodb.client.MongoClients;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.mongodb.config.AbstractMongoClientConfiguration;
import org.springframework.data.mongodb.core.MongoTemplate;
@Configuration
public class MongoConfig extends AbstractMongoClientConfiguration {
@Value("${spring.data.mongodb.database}")
private String appDatabase;
@Value("${spring.data.mongodb.uri}")
private String dbConnection;
@Override
protected String getDatabaseName() {
// Application default database name
return appDatabase;
}
@Bean
@Override
public MongoClient mongoClient() {
// MongoDB connection string
ConnectionString connectionString = new ConnectionString(dbConnection);
MongoClientSettings mongoClientSettings = MongoClientSettings.builder()
.applyConnectionString(connectionString)
.build();
return MongoClients.create(mongoClientSettings);
}
@Bean
public MongoTemplate mongoTemplate() {
return new MongoTemplate(mongoClient(), getDatabaseName());
}
}
Model for Storing Embeddings
Create new class KnowledgeBase.java under package com.slightinsight.assist.model which will be used as model for storing embeddings.
KnowledgeBase.java
package com.slightinsight.assist.model;
import java.util.List;
import org.springframework.data.annotation.Id;
import org.springframework.data.mongodb.core.mapping.Document;
import org.springframework.data.mongodb.core.mapping.Field;
@Document(collection = "KNOWLEDGE_BASE")
public class KnowledgeBase {
@Id
private String id;
@Field("text_data")
private String textData;
@Field("vector_data")
private List<Double> vectorData;
public KnowledgeBase() {
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getTextData() {
return textData;
}
public void setTextData(String textData) {
this.textData = textData;
}
public List<Double> getVectorData() {
return vectorData;
}
public void setVectorData(List<Double> vectorData) {
this.vectorData = vectorData;
}
}
Create Mongo Repository Interface
Create a new package for repositories com.slightinsight.assist.repository and add interface KnowledgeBaseRepository.java
KnowledgeBaseRepository.java
package com.slightinsight.assist.repository;
import org.springframework.data.mongodb.repository.MongoRepository;
import org.springframework.stereotype.Repository;
import com.slightinsight.assist.model.KnowledgeBase;
@Repository
public interface KnowledgeBaseRepository extends MongoRepository<KnowledgeBase, String> {
}
Update Assistant Service to Save embeddings to MongoDB
Now update AssistantService.java to add save embeddings into mongodb functionality.
AssistantService.java
package com.slightinsight.assist.service;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.atomic.AtomicReference;
import org.json.JSONArray;
import org.json.JSONObject;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import com.slightinsight.assist.model.KnowledgeBase;
import com.slightinsight.assist.model.Prompt;
import com.slightinsight.assist.repository.KnowledgeBaseRepository;
import software.amazon.awssdk.core.SdkBytes;
import software.amazon.awssdk.services.bedrockruntime.BedrockRuntimeAsyncClient;
import software.amazon.awssdk.services.bedrockruntime.BedrockRuntimeClient;
import software.amazon.awssdk.services.bedrockruntime.model.InvokeModelRequest;
import software.amazon.awssdk.services.bedrockruntime.model.InvokeModelResponse;
import software.amazon.awssdk.services.bedrockruntime.model.InvokeModelWithResponseStreamRequest;
import software.amazon.awssdk.services.bedrockruntime.model.InvokeModelWithResponseStreamResponseHandler;
@Service
public class AssistantService {
private static final String CLAUDE = "anthropic.claude-v2";
private static final String TITAN = "amazon.titan-embed-text-v1";
@Autowired
private BedrockRuntimeClient bedrockClient;
@Autowired
private BedrockRuntimeAsyncClient bedrockAsyncClient;
@Autowired
private KnowledgeBaseRepository knowledgeBaseRepository;
public String askAssistant(Prompt prompt) {
String response = "";
// Claude requires you to enclose the prompt as follows:
String enclosedPrompt = "Human: " + prompt.getQuestion() + "\n\nAssistant:";
if (prompt.getResponseType().equals("SYNC"))
response = syncResponse(enclosedPrompt);
else if (prompt.getResponseType().equals("ASYNC"))
response = asyncResponse(enclosedPrompt);
return response;
}
/*
* * Synchronous call to AI for text response
*/
private String syncResponse(String enclosedPrompt) {
String payload = new JSONObject().put("prompt", enclosedPrompt)
.put("max_tokens_to_sample", 200)
.put("temperature", 0.5)
.put("stop_sequences", List.of("\n\nHuman:")).toString();
InvokeModelRequest request = InvokeModelRequest.builder().body(SdkBytes.fromUtf8String(payload))
.modelId(CLAUDE)
.contentType("application/json")
.accept("application/json").build();
InvokeModelResponse response = bedrockClient.invokeModel(request);
JSONObject responseBody = new JSONObject(response.body().asUtf8String());
String generatedText = responseBody.getString("completion");
System.out.println("Generated text: " + generatedText);
return generatedText;
}
/*
* * Streaming call to AI for text response
*/
private String asyncResponse(String enclosedPrompt) {
var finalCompletion = new AtomicReference<>("");
var silent = false;
var payload = new JSONObject().put("prompt", enclosedPrompt).put("temperature", 0.8)
.put("max_tokens_to_sample", 300).toString();
var request = InvokeModelWithResponseStreamRequest.builder().body(SdkBytes.fromUtf8String(payload))
.modelId(CLAUDE).contentType("application/json").accept("application/json").build();
var visitor = InvokeModelWithResponseStreamResponseHandler.Visitor.builder().onChunk(chunk -> {
var json = new JSONObject(chunk.bytes().asUtf8String());
var completion = json.getString("completion");
finalCompletion.set(finalCompletion.get() + completion);
if (!silent) {
System.out.print(completion);
}
}).build();
var handler = InvokeModelWithResponseStreamResponseHandler.builder()
.onEventStream(stream -> stream.subscribe(event -> event.accept(visitor))).onComplete(() -> {
}).onError(e -> System.out.println("\n\nError: " + e.getMessage())).build();
bedrockAsyncClient.invokeModelWithResponseStream(request, handler).join();
return finalCompletion.get();
}
/*
* Saving embeddings into database
*/
public String saveEmbeddings(Prompt prompt) {
String payload = new JSONObject().put("inputText", prompt.getQuestion()).toString();
InvokeModelRequest request = InvokeModelRequest.builder().body(SdkBytes.fromUtf8String(payload)).modelId(TITAN)
.contentType("application/json").accept("application/json").build();
InvokeModelResponse response = bedrockClient.invokeModel(request);
JSONObject responseBody = new JSONObject(response.body().asUtf8String());
List<Double> vectorData = jsonArrayToList(responseBody.getJSONArray("embedding"));
KnowledgeBase data = new KnowledgeBase();
data.setTextData(prompt.getQuestion());
data.setVectorData(vectorData);
knowledgeBaseRepository.save(data);
return "Embeddings saved to database...!";
}
/*
* * Convert JSONArray to List<Double>
*/
private static List<Double> jsonArrayToList(JSONArray jsonArray) {
List<Double> list = new ArrayList<Double>();
for (int i = 0; i < jsonArray.length(); i++) {
list.add(jsonArray.getDouble(i));
}
return list;
}
}
Test saving embeddings to Vector Database
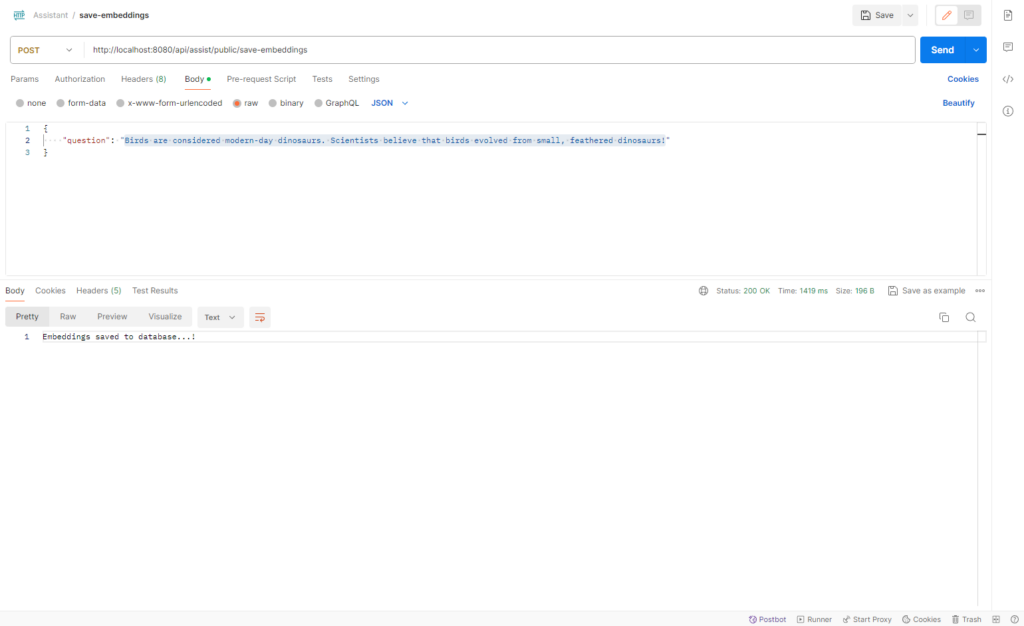
Run the spring-boot application, once completely up open postman and invoke the endpoint.
URL & Request Body
http://localhost:8080/api/assist/public/save-embeddings
Request Body:
{
"question": "Birds are considered modern-day dinosaurs. Scientists believe that birds evolved from small, feathered dinosaurs!"
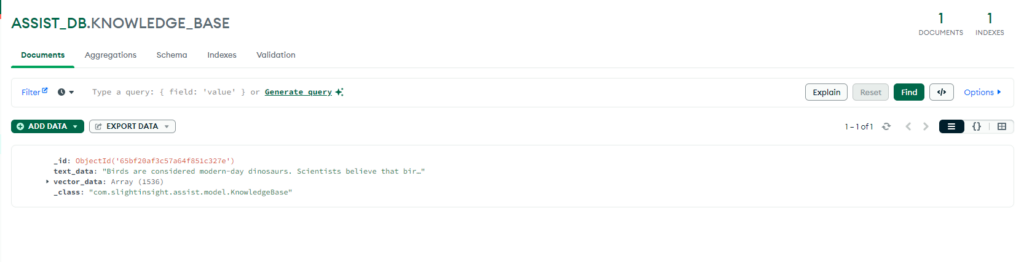
}If everything goes well, we will receive the response as below in postman:
Document should saved successfully in the MongoDB
Git Code: AssistantAI
Conclusion
In this blog, we have explored the concept of a vector database, specifically focusing on MongoDB Vector Database, and its integration with a Spring Boot application. We have also discussed the benefits of using MongoDB Vector Database and provided a high-level overview of the steps to create and store vector embeddings in MongoDB. By leveraging the capabilities of MongoDB Vector Database, developers can efficiently work with vectorized data within their applications.
Frequently Asked Questions
What is a vector database?
A Vector Database is designed to store, manage, and analyze vector data, making it ideal for applications dealing with complex relationships and patterns.
Why choose MongoDB for Vector Database?
MongoDB Vector Database, specifically Atlas Vector Search, allows for efficient storage, indexing, and searching of vector embeddings, seamlessly integrated with MongoDB Atlas’s powerful query engine.
How can I create a vector database in MongoDB?
To create a vector database in MongoDB, you need to set up a MongoDB Atlas account, create a cluster, enable Atlas Search, and define a collection for storing vector embeddings.




Leave a Reply
You must be logged in to post a comment.