
As artificial intelligence continues to advance, the need for domain-specific response systems has become increasingly important. These systems are designed to provide precise and contextually relevant answers in specialized fields, improving the user experience and efficiency. In this blog, we will share slight insight on how to create a domain-specific response system using AWS Bedrock Claude for AI capabilities, Retrieval-Augmented Generation (RAG) for enhanced responses, and MongoDB’s vector database for storing embeddings. By combining these technologies, you can build a robust and efficient system tailored to your specific domain needs.
This article is structured into multiple sections to streamline the stages involved in creating a domain-based AI assistant using RAG and prompt engineering.
- Amazon Bedrock: Revolutionizing Generative AI Applications
- Developing a Spring Boot Application with Amazon Bedrock API
- Leveraging Amazon Titan with Spring Boot: A Guide to Generating Embeddings
- Navigating the Vector Database Universe with Spring Boot and MongoDB
- The Art of Prompt Engineering: Optimizing GPT Models for Enhanced Performance
- Tailoring AI Responses for Your Domain
What is Retrieval-Augmented Generation (RAG)?
RAG is an innovative technique that enhances the capabilities of language models by incorporating external knowledge sources into the response generation process. In traditional generation-based models, the AI generates responses purely based on the training data it has seen. This can sometimes lead to inaccuracies or hallucinations, especially when the model encounters domain-specific or rare queries.
RAG addresses this issue by first retrieving relevant documents or information from an external knowledge base, such as a database, search engine, or any indexed data source. It then uses this retrieved information to augment the generation process, ensuring that the responses are both accurate and contextually relevant.
How RAG Works:
- Query Input: The process begins with the input query from the user. This could be a question, a request for information, or any prompt that requires a response from the AI system.
- Retrieval Phase: In the retrieval phase, the query is used to search an external knowledge source. This could be a document database, a vector store like MongoDB’s vector database, or even a search engine. The retrieval system finds the most relevant documents or data based on the query.
- Generation Phase: Once the relevant documents are retrieved, they are fed into the language model (like GPT-3, Claude, or another LLM) as context. The language model then generates a response that is informed by the retrieved documents. This ensures that the generated text is not only coherent but also backed by the most relevant and up-to-date information.
- Response Output: The final output is a response that is both contextually aware and accurate, making it far more reliable than a response generated purely by a language model without retrieval support.
Advantages of RAG:
- Improved Accuracy: By incorporating external data, RAG significantly improves the accuracy of the generated responses. This is particularly beneficial for domain-specific applications where precision is critical.
- Contextual Relevance: RAG ensures that responses are contextually relevant by retrieving information that is directly related to the user’s query. This reduces the risk of generating off-topic or irrelevant content.
- Scalability: RAG can easily be scaled across different domains and applications. By simply adjusting the retrieval source, you can tailor the AI’s responses to specific industries, such as healthcare, finance, legal, etc.
- Reduced Hallucination: One of the key challenges with generative models is the tendency to hallucinate—generating information that sounds plausible but is factually incorrect. RAG mitigates this issue by grounding the generated content in real, retrieved data.
Let’s Enhance our AI Assistant to respond on Domain Specific Knowledge
Now that all the ingredients are ready, in this article, we will enhance our application to use the Retrieval-Augmented Generation (RAG) concept to generate AI responses based on domain knowledge. RAG allows us to leverage external knowledge sources, making our AI responses more accurate and contextually relevant.
Add new API endpoint
Update “AssistantController.java” to add a new API endpoint for receiving domain related response.
AssistantController.java
package com.slightinsight.assist.web;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import com.slightinsight.assist.model.Prompt;
import com.slightinsight.assist.service.AssistantService;
@RestController
@RequestMapping("/api/assist")
public class AssistantController {
@Autowired
private AssistantService assistantService;
@GetMapping(value = "/public/ask")
public ResponseEntity<String> askAssistant(@RequestBody Prompt prompt) {
String response = assistantService.askAssistant(prompt);
return new ResponseEntity<String>(response, HttpStatus.OK);
}
@PostMapping(value = "/public/save-embeddings")
public ResponseEntity<String> saveEmbeddings(@RequestBody Prompt prompt) {
String response = assistantService.saveEmbeddings(prompt);
return new ResponseEntity<String>(response, HttpStatus.OK);
}
@GetMapping(value = "/public/knowledgebase/ask")
public ResponseEntity<String> askExpertAssistant(@RequestBody Prompt prompt) {
String response = assistantService.askExpertAssistant(prompt);
return new ResponseEntity<String>(response, HttpStatus.OK);
}
}
Create service for searching Vector database
Add new class “KnowledgeBaseVectorSearch.java” for searching vector database. The main function of this class is to take user query in embeddings format and extract relevant context in text format.
KnowledgeBaseVectorSearch.java
package com.slightinsight.assist.service;
import java.util.List;
import static com.mongodb.client.model.Aggregates.*;
import static com.mongodb.client.model.Projections.*;
import static com.mongodb.client.model.search.SearchPath.fieldPath;
import static java.util.Arrays.asList;
import org.bson.conversions.Bson;
import org.bson.Document;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;
import com.mongodb.client.AggregateIterable;
import com.mongodb.client.MongoClient;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import com.mongodb.client.model.search.FieldSearchPath;
@Service
public class KnowledgeBaseVectorSearch {
@Autowired
private MongoClient mongoClient;
@Value("${spring.data.mongodb.database}")
private String appDatabase;
public AggregateIterable<Document> findByVectorData(List<Double> queryVector) {
MongoDatabase database = mongoClient.getDatabase(appDatabase);
MongoCollection<Document> collection = database.getCollection("KNOWLEDGE_BASE");
String indexName = "vector_index";
FieldSearchPath fieldSearchPath = fieldPath("vector_data");
int numCandidates = 10;
int limit = 1;
List<Bson> pipeline = asList(
vectorSearch(fieldSearchPath, queryVector, indexName, numCandidates, limit),
project(fields(exclude("_id"), include("text_data"), include("active"),
metaVectorSearchScore("score"))));
return collection.aggregate(pipeline);
}
}
Update Assistant AI Service
Create new method “askExpertAssistant” to add functionality related to RAG. We will add code to convert user query into embeddings and then search it against vector database to fetch relevant context. Next update the user prompt to add the context and sent to LLM to generate the domain specific response.
AssistantService.java
package com.slightinsight.assist.service;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.atomic.AtomicReference;
import org.bson.Document;
import org.json.JSONArray;
import org.json.JSONObject;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import com.mongodb.client.AggregateIterable;
import com.slightinsight.assist.model.KnowledgeBase;
import com.slightinsight.assist.model.Prompt;
import com.slightinsight.assist.repository.KnowledgeBaseRepository;
import software.amazon.awssdk.core.SdkBytes;
import software.amazon.awssdk.services.bedrockruntime.BedrockRuntimeAsyncClient;
import software.amazon.awssdk.services.bedrockruntime.BedrockRuntimeClient;
import software.amazon.awssdk.services.bedrockruntime.model.InvokeModelRequest;
import software.amazon.awssdk.services.bedrockruntime.model.InvokeModelResponse;
import software.amazon.awssdk.services.bedrockruntime.model.InvokeModelWithResponseStreamRequest;
import software.amazon.awssdk.services.bedrockruntime.model.InvokeModelWithResponseStreamResponseHandler;
@Service
public class AssistantService {
private static final String CLAUDE = "anthropic.claude-v2";
private static final String TITAN = "amazon.titan-embed-text-v1";
@Autowired
private BedrockRuntimeClient bedrockClient;
@Autowired
private BedrockRuntimeAsyncClient bedrockAsyncClient;
@Autowired
private KnowledgeBaseRepository knowledgeBaseRepository;
@Autowired
private KnowledgeBaseVectorSearch knowledgeBaseVectorSearch;
public String askAssistant(Prompt prompt) {
String response = "";
// Claude requires you to enclose the prompt as follows:
String enclosedPrompt = "Human: " + prompt.getQuestion() + "\n\nAssistant:";
if (prompt.getResponseType().equals("async"))
response = asyncResponse(enclosedPrompt);
else if (prompt.getResponseType().equals("sync"))
response = syncResponse(enclosedPrompt);
return response;
}
/*
* * Synchronous call to AI for text response
*/
private String syncResponse(String enclosedPrompt) {
String payload = new JSONObject().put("prompt", enclosedPrompt)
.put("max_tokens_to_sample", 200)
.put("temperature", 0.5)
.put("stop_sequences", List.of("\n\nHuman:")).toString();
InvokeModelRequest request = InvokeModelRequest.builder().body(SdkBytes.fromUtf8String(payload))
.modelId(CLAUDE)
.contentType("application/json")
.accept("application/json").build();
InvokeModelResponse response = bedrockClient.invokeModel(request);
JSONObject responseBody = new JSONObject(response.body().asUtf8String());
String generatedText = responseBody.getString("completion");
System.out.println("Generated text: " + generatedText);
return generatedText;
}
/*
* * Streaming call to AI for text response
*/
private String asyncResponse(String enclosedPrompt) {
var finalCompletion = new AtomicReference<>("");
var silent = false;
var payload = new JSONObject().put("prompt", enclosedPrompt).put("temperature", 0.8)
.put("max_tokens_to_sample", 300).toString();
var request = InvokeModelWithResponseStreamRequest.builder().body(SdkBytes.fromUtf8String(payload))
.modelId(CLAUDE).contentType("application/json").accept("application/json").build();
var visitor = InvokeModelWithResponseStreamResponseHandler.Visitor.builder().onChunk(chunk -> {
var json = new JSONObject(chunk.bytes().asUtf8String());
var completion = json.getString("completion");
finalCompletion.set(finalCompletion.get() + completion);
if (!silent) {
System.out.print(completion);
}
}).build();
var handler = InvokeModelWithResponseStreamResponseHandler.builder()
.onEventStream(stream -> stream.subscribe(event -> event.accept(visitor))).onComplete(() -> {
}).onError(e -> System.out.println("\n\nError: " + e.getMessage())).build();
bedrockAsyncClient.invokeModelWithResponseStream(request, handler).join();
return finalCompletion.get();
}
/*
* Saving embeddings into database
*/
public String saveEmbeddings(Prompt prompt) {
String payload = new JSONObject().put("inputText", prompt.getQuestion()).toString();
InvokeModelRequest request = InvokeModelRequest.builder().body(SdkBytes.fromUtf8String(payload)).modelId(TITAN)
.contentType("application/json").accept("application/json").build();
InvokeModelResponse response = bedrockClient.invokeModel(request);
JSONObject responseBody = new JSONObject(response.body().asUtf8String());
List<Double> vectorData = jsonArrayToList(responseBody.getJSONArray("embedding"));
KnowledgeBase data = new KnowledgeBase();
data.setTextData(prompt.getQuestion());
data.setVectorData(vectorData);
knowledgeBaseRepository.save(data);
return "Embeddings saved to database...!";
}
/*
* * Convert JSONArray to List<Double>
*/
private static List<Double> jsonArrayToList(JSONArray jsonArray) {
List<Double> list = new ArrayList<Double>();
for (int i = 0; i < jsonArray.length(); i++) {
list.add(jsonArray.getDouble(i));
}
return list;
}
public String askExpertAssistant(Prompt prompt) {
/*
* Fetch relavent content from vector database
* 1. Convert prompt to embeddings
*/
String payload = new JSONObject().put("inputText", prompt.getQuestion()).toString();
InvokeModelRequest request = InvokeModelRequest.builder().body(SdkBytes.fromUtf8String(payload)).modelId(TITAN)
.contentType("application/json").accept("application/json").build();
InvokeModelResponse response = bedrockClient.invokeModel(request);
JSONObject responseBody = new JSONObject(response.body().asUtf8String());
List<Double> vectorQuery = jsonArrayToList(responseBody.getJSONArray("embedding"));
/* 2. Query vector database */
AggregateIterable<Document> context = knowledgeBaseVectorSearch.findByVectorData(vectorQuery);
/* 3. Return relevant content */
String enclosedPrompt = "Human:\n\n" + prompt.getQuestion();
for (Document document : context) {
enclosedPrompt = enclosedPrompt + "<context>" + document.getString("text_data") + "</context>\n";
}
enclosedPrompt = enclosedPrompt + "\n\n Assistant:";
System.out.println(enclosedPrompt);
/* 4. Generate response using Context */
var finalCompletion = new AtomicReference<>("");
var silent = false;
var queryPayload = new JSONObject().put("prompt", enclosedPrompt).put("temperature", 0.0)
.put("max_tokens_to_sample", 200).toString();
var queryRequest = InvokeModelWithResponseStreamRequest.builder().body(SdkBytes.fromUtf8String(queryPayload))
.modelId(CLAUDE).contentType("application/json").accept("application/json").build();
var visitor = InvokeModelWithResponseStreamResponseHandler.Visitor.builder().onChunk(chunk -> {
var json = new JSONObject(chunk.bytes().asUtf8String());
var completion = json.getString("completion");
finalCompletion.set(finalCompletion.get() + completion);
if (!silent) {
System.out.print(completion);
}
}).build();
var handler = InvokeModelWithResponseStreamResponseHandler.builder()
.onEventStream(stream -> stream.subscribe(event -> event.accept(visitor))).onComplete(() -> {
}).onError(e -> System.out.println("\n\nError: " + e.getMessage())).build();
bedrockAsyncClient.invokeModelWithResponseStream(queryRequest, handler).join();
return finalCompletion.get();
}
}
Testing the Application
We can run this app by issuing below command:
Command
mvn spring-boot:run
Adding Domain Knowledge in Vector Database:
Save your domain specific information in Vector database. I am from mainframe background, and have used IOF tool for mainframe jobs monitoring. Let me save this information in vector database as embeddings.
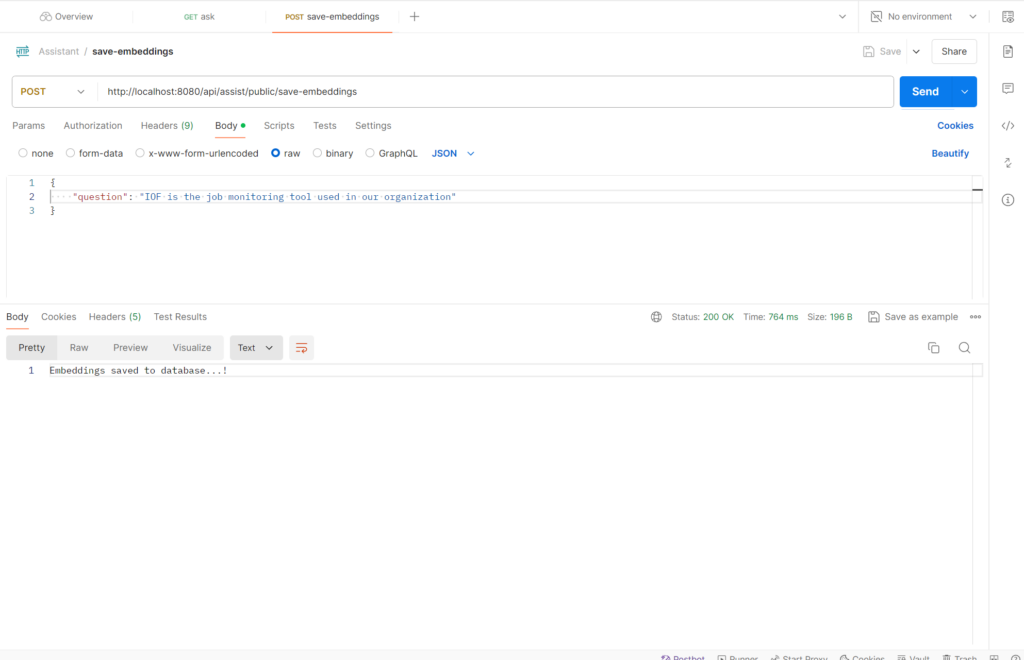
URL & Request Body
http://localhost:8080/api/assist/public/save-embeddings
{
"question": "IOF is the job monitoring tool used in our organization"
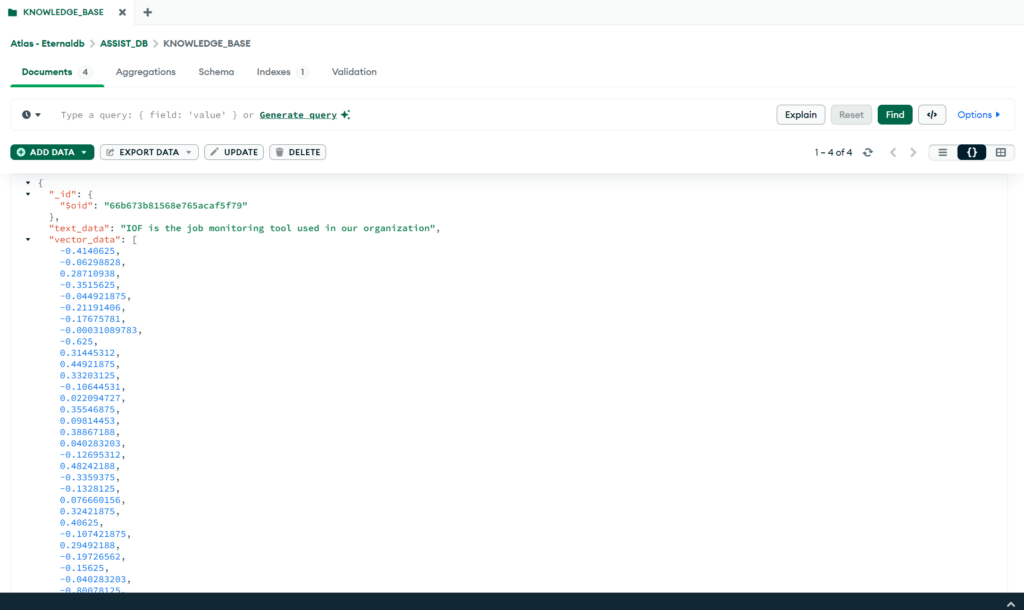
}Refer below images for postman response and saved data as embeddings in mongodb vector database.
AI response – Without RAG (Domain Knowledge):
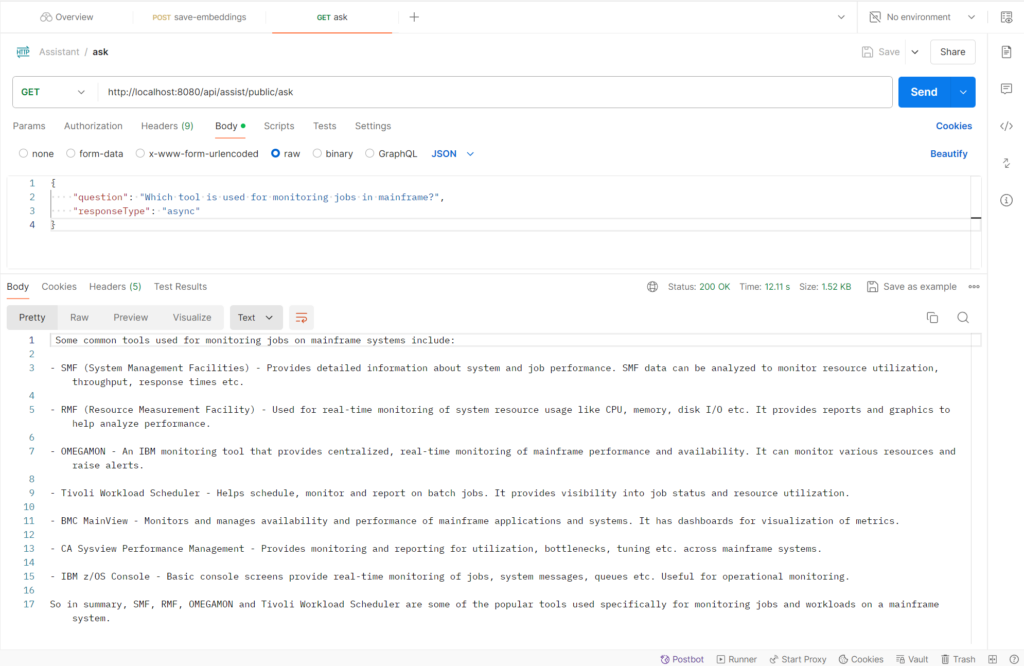
Lets ask our AI app about job monitoring tool.
URL & Request Body
http://localhost:8080/api/assist/public/ask
{
"question": "Which tool is used for monitoring jobs in mainframe?",
"responseType": "async"
}If everything goes well, we will receive the response as below in postman:
AI response – With RAG (Domain Knowledge):
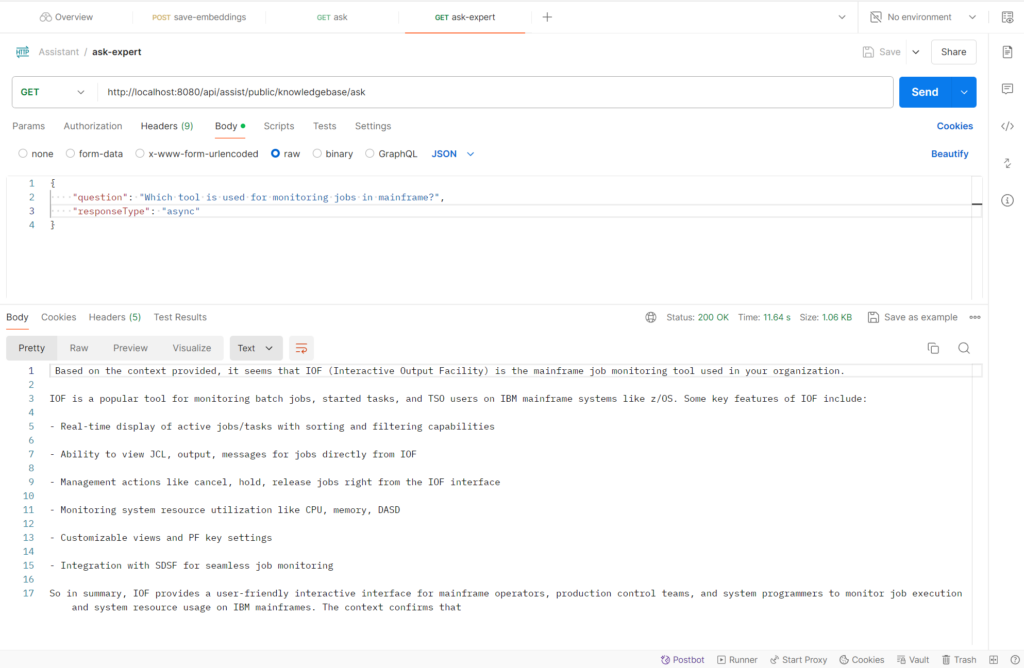
Now lets ask the same question to our Expert AI Assistant app.
URL & Request Body
http://localhost:8080/api/assist/public/knowledgebase/ask
{
"question": "Which tool is used for monitoring jobs in mainframe?",
"responseType": "async"
}As we can clearly see, now the response is based on the domain knowledge that was stored in our vector database.
Git Code: AssistantAI
Conclusion
By combining AWS Bedrock Claude, AWS Titan, and MongoDB’s vector database with the Retrieval-Augmented Generation (RAG) concept, you can create a powerful domain-specific response system. This setup leverages advanced language understanding capabilities, accurate and up-to-date information retrieval, and efficient storage and retrieval of embeddings. The result is a system that provides precise, contextually relevant, and accurate responses tailored to your specific domain needs.
Integrating these technologies opens up a world of possibilities for building intelligent applications across various industries. Whether you’re working in healthcare, finance, education, or any other domain, this approach can significantly enhance the quality and relevance of your AI-powered solutions. Stay tuned for more insights and tutorials on leveraging cutting-edge technologies in your projects!
Frequently Asked Questions
What is the main difference between RAG and traditional language models?
The primary difference between RAG and traditional language models is that RAG combines retrieval-based methods with generation-based models. Traditional language models generate responses solely based on their training data, which can sometimes lead to inaccuracies or irrelevant content. RAG, on the other hand, first retrieves relevant information from external knowledge sources and then uses this information to generate more accurate and contextually relevant responses.
What types of applications benefit the most from using RAG?
RAG is particularly beneficial for applications that require domain-specific accuracy, such as legal document analysis, healthcare information systems, customer support chatbots, and financial services. Any application where the accuracy and contextual relevance of responses are critical can significantly benefit from RAG.
How does RAG handle new or rare information that wasn’t in the model’s training data?
RAG excels at handling new or rare information by retrieving up-to-date and relevant documents from an external knowledge base. Even if the model wasn’t trained on specific data, RAG can access and use this information in the generation phase, allowing the AI to provide accurate responses based on the latest available data.
Can RAG be scaled to handle large datasets and multiple domains?
Yes, RAG can be scaled to handle large datasets and multiple domains. The retrieval system can be configured to manage vast amounts of data efficiently, while the generation model can be adapted to different domains by retrieving domain-specific documents. By leveraging cloud-based solutions like AWS and MongoDB Atlas, you can ensure that your RAG implementation is scalable and can handle increasing loads as your data and application requirements grow.



Leave a Reply
You must be logged in to post a comment.